
The machine room
I's fastest gains aren't in the spectacular applications. They're in the work nobody describes.

This is Article 3 in a nine-part series: The Urban Professional in the Age of AI, based on The Urban Operating System.
1. The gap · 2. Three paradigms · 3. The machine room ← you are here · 4. Project memory · 5. Options and numbers · 6. The digital twin · 7. Participation · 8. Five levels · 9. The question behind the tools
A project manager closes her laptop at 18:07. The day did not fail because the strategic questions were too hard. It failed because the operational ones consumed it entirely.
There were two meetings that needed notes and action points. A legal comment on a draft cooperation agreement that had to be checked against an older version. Three resident emails waiting for a careful response. A briefing note for tomorrow’s steering group that still had to be written. A spreadsheet with comments from three departments that did not yet align. A new colleague who needed the background of a project that began before he joined.
None of this is glamorous. All of it is real work. And in most planning organisations today, it crowds out everything else.
Urban practice describes itself through its visible moments: the political choice, the design review, the participation evening, the strategic memo. But most of the profession runs on a less visible layer underneath. Notes. Summaries. First drafts. Cross-checks. Handovers. Small acts of translation between legal language, political language, technical language and plain language. This is the machine room.
And this is where AI is likely to deliver the fastest returns, at least at the level of individual tasks.1
The hidden economics of urban work
Urban work is expensive in a very specific way. Not because each task is intellectually extraordinary, but because there are so many small translation costs between one part of the process and another.
A meeting produces discussion, but not yet a shared record. A policy document contains relevant passages, but not yet the comparison a programme manager needs. A participation process generates raw input, but not yet a synthesis a councillor can use. A legal text may contain the answer, but only after someone finds the relevant clause, checks whether it is still current, and explains it in plain language. Every one of those conversions takes time. Every one interrupts something else.
This is why the operational layer matters more than it looks. It is not administration around the real work. It is part of the real work. It is the layer through which the analytical, legal, political and social dimensions of urban practice are made usable by others.
The machine room is also where fragmentation becomes visible first. If data is badly structured, the first sign is usually not a failed digital twin. It is the analyst who cannot compare two policy versions quickly. If governance is weak, the first sign is usually not a scandal. It is the team that has no routine for checking AI-assisted output before it leaves the office. If institutional memory is poor, the first sign is usually not a conflict. It is the new project lead who asks why a decision was made and discovers that the answer lives only in someone’s inbox.
That is also why starting here is rational. The machine room sits close to everyday practice, exposes organisational weaknesses quickly, and offers improvements that teams can test without redesigning the whole institution.
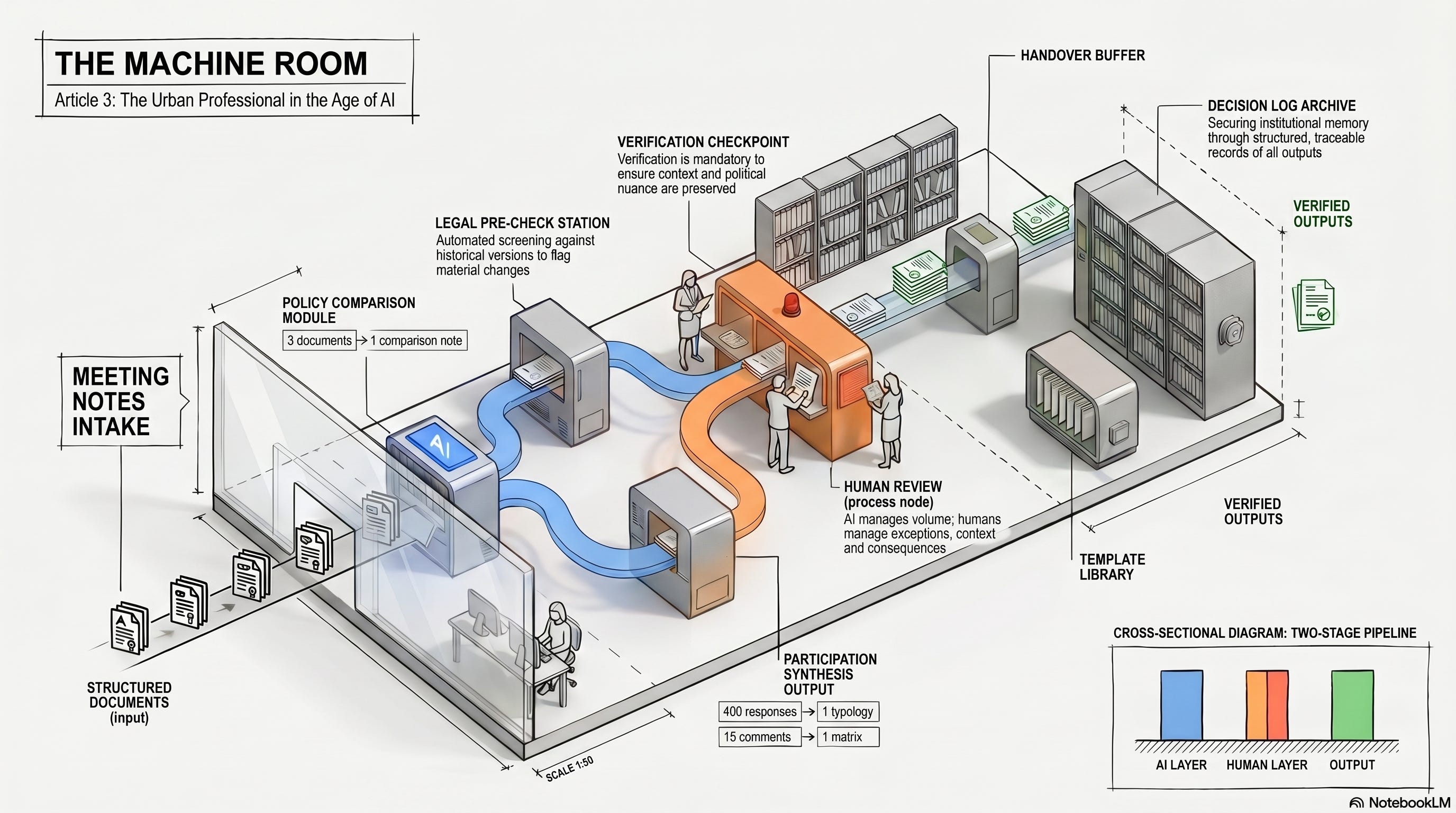
Four ordinary cases
The operational layer is broader than it first appears. It includes meeting notes, action lists, briefings, Q&A documents, email drafts, decision logs, first-pass policy comparisons, legal pre-checks, subsidy requirement checks and structured summaries of consultation input. It includes the routine work of turning long text into short text, technical text into readable text, dispersed comments into a single version.
These tasks are not equal in risk, but they share a family resemblance. They involve reading, structuring, comparing, extracting, drafting and translating. They are often repetitive in form, even when the consequences are not. They are exactly the kind of work where AI already performs well, provided the material is available and the verification routine is sound. The same research that documents the gains also documents what happens outside this zone: for tasks that fall beyond the frontier, AI assistance makes professionals approximately 19 percent less likely to reach the correct solution than colleagues working without it. Knowing which side of the boundary a task sits on is not a technicality. It is the professional judgment that makes the machine room safe to operate.2
Consider four ordinary cases.
A housing strategist needs a two-page note by 09:00 comparing a regional housing deal, a municipal coalition agreement and a newly revised affordability definition. The work is not to invent a theory of housing. It is to identify overlap, tension, missing delivery mechanisms and political exposure. AI can usually produce a first structured pass in minutes, provided the documents are accessible and the task is well framed.
A planning lawyer needs to know whether a new draft clause differs materially from the agreement version discussed three weeks earlier. AI can mark the differences, group them by legal significance and flag the ones that change obligations rather than wording.
A participation advisor needs to turn four hundred written responses into a usable typology of concerns, without pretending that frequency alone equals importance. AI can cluster themes, extract representative formulations and separate practical objections from trust-based ones, leaving the advisor time to judge what the themes actually mean.3
A project team receives fifteen comments from different departments on a concept document. AI can merge, deduplicate, identify conflicts and produce a structured comment matrix instead of a mess of tracked changes.
In each case, the value is not only speed. It is sequence. Work that used to consume the first half of a process can now be moved earlier, creating more protected time for the judgement that follows. Urban professionals are rarely short of important judgement calls. They are short of the time in which to make them well.
Why this is not just an efficiency story
There is a narrow version of this argument: automate the routine, free up hours, increase output. That is true, but it misses the more important claim.
The machine room changes the quality of professional attention.
A tired professional does not only work slower. A tired professional narrows. The first thing to disappear under time pressure is not formal compliance. It is interpretation. The second reading of a difficult response. The careful phrasing of a politically sensitive note. The effort to check whether a neutral-sounding objection is actually a signal of deeper distrust.
When operational overload dominates the day, analysis becomes thinner even if all formal tasks are completed. This is why the machine room is not a side issue. It shapes the conditions under which judgement happens.
There is a further point. The operational layer is where many organisations silently standardise their own quality. A team that produces consistent notes, clear action lists, traceable decisions and usable handovers will usually make better strategic choices than a team with the same intelligence but weak operational discipline. AI does not create that discipline by itself. It can, however, lower the cost of maintaining it.
That makes the machine room a governance issue as much as a tooling issue. The question is not only whether a model can summarise a meeting. The question is whether the organisation has decided what a meeting summary must contain: decisions taken, assumptions left open, owners, deadlines, unresolved tensions. AI can fill a template. It cannot decide what counts as a good record unless someone has done that institutional work first.
That institutional work is harder than it sounds. In most planning organisations, the operational layer has no real owner. The meeting has no assigned note-taker. The decision log has no standard. The briefing template does not exist. This is not ignorance. It is a management choice that has never been made explicitly. AI does not solve that. It inherits it.
There is also a prior condition that is easy to understate. The machine room works well when the documents it processes are accessible, structured and findable. In organisations where project files are scattered across personal drives, email threads and SharePoint folders that nobody fully navigates, the first problem is not which AI tool to use. It is whether the material the tool needs actually exists in a usable form. Research on AI rollout readiness consistently finds a large gap between how many organisations believe they are AI-ready and how many actually are at the point of implementation.4 The machine room inherits whatever information hygiene the organisation has. It does not create hygiene that does not exist.
The risk of fluency without reliability
There is, however, a real risk in making this layer easier. The easier it becomes to produce acceptable-looking operational output, the easier it becomes to confuse fluency with reliability.
An AI-generated meeting summary may read more clearly than a hurried human one and still omit the single moment that matters most. A legal first draft may look rigorous and still contain a fabricated reference. The legal context makes this concrete: a database tracking global court decisions involving AI-generated hallucinations counted over 1,174 cases by early 2026, with approximately 90 percent of those decisions issued in the previous year alone, and US courts imposing over $145,000 in sanctions in the first quarter of 2026. The pattern is consistent: the output looks authoritative, the professional does not check, and the error only surfaces when it causes damage.5 A resident response may be translated into calm administrative language and in the process lose the social meaning that gave it weight.
The cost of verification is real and often underestimated. Most of the measured productivity gains in the research literature are task-level gains. At organisational level, those gains are frequently offset by the time required to review, correct and re-check outputs. The net improvement is smaller and harder to see than headline figures suggest.6
Article 1 argued that verification needs to be built into every AI-assisted workflow. That matters here more than anywhere else, because the operational layer creates the highest volume of outputs and therefore the greatest temptation not to check them properly.
A useful distinction helps: AI can be trusted with first-pass structuring. It cannot be trusted with final-pass responsibility.
Let the system produce the summary, but a human checks whether the one politically decisive sentence is there. Let the system compare the documents, but a human checks the clauses that carry legal or financial consequence. Let the system cluster the consultation input, but a human checks whether the emotional centre of the material has survived the synthesis.7
The problem is not that AI outputs are always wrong. Most of the time, they are good enough to pass. That is exactly why critical reading weakens if no verification routine is imposed. Cognitive surrender does not announce itself. It arrives gradually, dressed as productivity. Controlled experiments show that people follow incorrect AI answers around 80 percent of the time, and that confidence goes up rather than down when AI is involved, even when the AI is wrong.8
There is a second, less discussed risk. A machine room that works lowers the threshold for output. Documents get sent faster. Drafts leave the desk sooner. The friction that used to slow things down also used to create moments for reconsideration. Removing it is not always a net gain.
And a third: the operational layer, once built on a particular platform, becomes difficult to move. Prompts, templates, archive logic and team habits accumulate around specific tools. That is not an argument against starting. It is an argument for choosing carefully and maintaining the ability to audit and exit what you build.
The apprenticeship problem
One objection deserves serious attention. Much professional judgement is built by doing exactly the first-pass work that AI now handles well. Early career staff learn by drafting notes, comparing texts, structuring comments and doing initial legal or policy reads. If those tasks disappear too quickly, what happens to judgement later?
The signals are uncomfortable. Entry-level hiring in AI-exposed professional fields dropped significantly between 2022 and 2024, as organisations found they could handle first-pass work without adding junior staff.9 Medical research on AI-assisted clinical work documents a parallel deskilling pattern: skills not practised atrophy, and practitioners become dependent on tools to complete tasks they previously performed independently. The concern is not hypothetical. It has a professional formation logic: you cannot learn to read a room, sense when a technically clean proposal has no political traction, or recognise what a neutral-sounding objection actually signals, by reviewing AI output summaries of those situations.
There is a counterargument. Research on AI-assisted customer support found that novice workers gained the most, with 34 percent productivity improvements and suggestive evidence of faster skill transfer from senior to junior workers. In the right conditions, AI can accelerate learning rather than prevent it. But the conditions matter enormously. The learning benefit accrues when junior staff interact with the raw material and the AI output together, not when they only see the finished product.10
The honest formulation is this: both dynamics are possible, and the direction depends entirely on how organisations design the work. The machine room as training ground requires deliberate construction. Junior staff should compare their own first pass against the system’s, learn where the model over-compressed disagreement or missed contextual significance, and develop the habit of knowing what good looks like before they accept what fast produces.
That design choice will not happen by default. In most organisations, the path of least resistance is to give junior staff AI outputs to review and call it efficiency. That is the path toward a profession that can produce fluent documents and gradually loses the capacity to judge them.
What comes next, and why it changes the stakes
The machine room described in this article reflects the current moment: professionals using AI to accelerate first-pass work, with humans retaining final-pass responsibility. That is the right arrangement for now. It will not describe the situation in three years.
Two trajectories in model development are moving simultaneously, and they pull in different directions.
The first is improvement in grounded, document-anchored tasks. For work where the model has a source document to work from, hallucination rates on leading models have dropped sharply, from fifteen to twenty percent two years ago to below one percent on some benchmarks for summarisation and extraction tasks. This is precisely the zone where the machine room operates: processing what already exists, comparing what is in front of it, flagging differences between two known versions. That improvement is real and continuing. The tasks in the four cases described in this article will become more reliable, not less, as models improve.
The second trajectory moves in the opposite direction. Models optimised for extended reasoning, the frontier systems being positioned as the next generation of professional AI, consistently hallucinate more on open-ended factual questions than simpler models do. When a reasoning model does not have a source document to anchor it, it fills the gap with statistically plausible confabulation at higher rates than its predecessors. This matters for the machine room because the boundary between anchored tasks and open-ended tasks is not always obvious. A policy comparison is anchored. A question about whether a legal clause is consistent with emerging case law trends is not. As the machine room expands in scope and confidence, the risk is that professionals start delegating tasks that look like the first category but are actually the second.11
The shift from assistive to agentic AI compounds both trajectories. Systems that monitor documents, flag changes, draft notes and route outputs without an explicit prompt per task are already in early deployment. For the machine room, this means outputs arrive faster, at higher volume, and without the natural pause that a deliberate prompt used to create. The verification habits that are difficult to maintain today will be structurally harder to maintain when the system runs continuously. Building those habits now, while the workflow is still slow enough to make them visible, is not just good practice for today. It is the preparation that later autonomous operation requires.
For apprenticeship, the timeline is the most uncomfortable part. The tasks disappearing from junior portfolios now are document-level: first drafts, comparisons, structured summaries. As reasoning and agentic systems mature, the next layer follows: first-pass research synthesis, initial stakeholder mapping, early scenario framing. These are precisely the tasks through which a junior planner currently learns to read a project, understand its politics, and develop the situational awareness that no amount of AI output review can substitute for. The organisations that do not deliberately redesign professional formation in the next two to three years will find the window has closed. The tools will have arrived before the pedagogy.
None of this is a reason to wait. It is a reason to start with more seriousness than the word “machine room” might suggest.
What a functional machine room looks like
A functional machine room has standard prompts for recurring tasks. It has templates for meeting notes, policy comparisons, first-pass legal checks, consultation summaries and handovers. It has named risk categories that always trigger human review: legal references, financial assumptions, policy compliance claims, and any statement that could materially shape a decision. It has a clear archive logic so outputs can be found, checked and reused.
Most importantly, it has a clear division of labour.
The machine handles volume, first-pass structure and repetitive translation. The professional handles judgement, exception, context and consequence.
That division sounds obvious. But most teams do not work this way. Either they keep everything manual and lose time, or they accept polished AI output too quickly because the document looks finished. The right arrangement is more disciplined than either extreme.
A planning organisation does not need a full AI strategy to begin here. It needs one workflow, one standard and one review routine. Start with something frequent and low-risk enough to learn from: a weekly policy comparison, meeting note processing, a briefing draft, a resident Q&A document. Then make one decision about quality: what must every output of this type contain? Then make one decision about review: which parts always need a human check?
That is enough to begin. But one condition has to be in place first: someone has to own the standard. Not in theory. In practice. The verification routine that depends on individual discipline under time pressure is the one that will not hold. The one that is assigned, scheduled and checked is the one that might.
One more honest observation. The gains from a well-run machine room are real but largely invisible from the outside. Better notes, faster comparisons, cleaner handovers: these do not appear in a progress report or a budget review. The organisations that build this layer will rarely be able to point to it and say: that is where the quality improvement came from. That invisibility is part of why it does not happen more often. It is also, in a quiet way, why it matters.
Article 2 described three institutional logics that now operate simultaneously inside most planning organisations. The machine room is where those logics meet every day, in practice, at the level of documents and decisions. It is also where the gap between what AI can do and what organisations have built the conditions to use is widest, most visible and most immediately closeable.
That last point needs a qualification. “Most immediately closeable” is relative to scale. For a team of twenty with a clear project structure and accessible files, the starting conditions exist. For a two-person team in a small municipality, or a large department where documents are dispersed across a decade of inconsistent filing, the machine room requires a prior investment in basic information hygiene that has nothing to do with AI.
In most organisations, the honest trigger for actually doing this is not strategic insight. It is a mistake. A decision that was never recorded. A handover that failed because the context had not been written down. A resident who discovered that what they said in 2022 had not survived the synthesis. That is what creates the organisational will to fix the layer underneath.
The temptation in every technological transition is to start where the story is most exciting. The discipline is to start where the institutional return is highest.
For urban professionals, that place is usually not the dazzling visualisation or the autonomous agent. It is the notes that are not written. The comparisons that take too long. The email that shapes trust more than the strategy document. The first-pass synthesis that absorbs three days and leaves no time for thought.
Unglamorous. Load-bearing. The place where the transition becomes real.
Next in this series: Project memory. Planning organisations do not only have a data problem. They have a continuity problem. When people leave, much of what mattered leaves with them.
Yes, I used AI. Here’s how.
This post was shaped with the help of AI, which supported the process in several ways: conducting background research, contributing to the writing itself, acting as a critical sounding board along the way, designing the carousel for the LinkedIn post, and creating the image in this article. The ideas, choices, and conclusions remain my own, but the thinking was sharpened in conversation with AI.
Notes
Brynjolfsson, E., Li, D. & Raymond, L. (2025). Generative AI at Work. Quarterly Journal of Economics, 140(2), 889-942. NBER Working Paper 31161. nber.org/papers/w31161. Average 14% productivity gain across 5,179 customer support agents; 34% for novice workers; near-zero for the most experienced. Aldasoro, I. et al. (2026). AI Adoption and Firm Productivity. CEPR VoxEU / BIS. Cited in Stanford HAI, AI Index Report 2026, Ch. 4, Fig. 4.4.28. Study of 12,000 European firms: +4% labour productivity from AI adoption, amplified by training. Yotzov, I. et al. (2026). Firm Data on AI. NBER Working Paper 34836. nber.org/papers/w34836. Nine in ten executives across 6,000 firms report no measurable productivity impact despite 69% active AI use.
Dell’Acqua, F. et al. (2023). Navigating the Jagged Technological Frontier. Harvard Business School Working Paper 24-013. hbs.edu/faculty. Within the frontier: +12.2% task completion, +25.1% speed, +40% quality. Outside the frontier, a separate study found the inverse: Becker, M. et al. (2025). Measuring the Impact of AI on Software Engineers’ Productivity. METR. Cited in Stanford HAI, AI Index Report 2026, Ch. 4, Fig. 4.4.27. Experienced developers became 19% slower with AI assistance, with a gap between perceived helpfulness and actual performance.
Raymond, C.M. et al. (2025). Uses, opportunities and risks of artificial intelligence in participatory urban planning. Discover Cities, Springer. doi.org/10.1007/s44327-025-00137-4. Othengrafen, F., Sievers, L. & Reinecke, E. (2025). From Vision to Reality: The Use of AI in Different Urban Planning Phases. Urban Planning, 10. cogitatiopress.com/urbanplanning/article/view/8576. Both studies are the empirical basis for the participation advisor case. Raymond et al. find that planners see AI as most useful for summarising, reporting and analysing feedback.
The readiness gap between perceived and actual AI-readiness at the point of rollout is documented across multiple enterprise AI adoption studies from 2025 to 2026, including findings cited in the AI Index Report 2026 (Stanford HAI) and enterprise data governance research. The consistent finding: organisations overestimate their data and infrastructure readiness before implementation.
Charlotin, D. (2026). AI Hallucinations in Legal Filings database. HEC Paris / Sciences Po. damiencharlotin.com/hallucinations. Over 1,174 decisions worldwide by early 2026; approximately 90% issued in the previous year. US courts imposed over $145,000 in sanctions in Q1 2026. Illinois Courts guidance (January 2026) confirms that lawyers retain professional responsibility for verifying all cited cases. illinoiscourts.gov
The gap between task-level productivity gains and organisational-level impact is the central finding of the macro-level studies surveyed in Stanford HAI, AI Index Report 2026, Ch. 4, Fig. 4.4.28. Yotzov et al. (2026) found that nine in ten executives reported no measurable productivity impact despite active AI use, consistent with Brynjolfsson’s “J-curve” hypothesis that organisations absorb adoption costs before gains materialise. See note 1 for full citations.
Romero, A. (2026). A New Wharton Study on AI Warns of a Growing Problem: Cognitive Surrender. The Algorithmic Bridge. thealgorithmicbridge.com. Romero’s distinction between cognitive offloading (strategic delegation while retaining judgement) and cognitive surrender (accepting output because it looks authoritative) is the conceptual basis for the first-pass / final-pass distinction in this article.
Wharton School, University of Pennsylvania (2026). Thinking, Fast, Slow, and Artificial: How AI is Reshaping Human Reasoning and the Rise of Cognitive Surrender. papers.ssrn.com/sol3/papers.cfm?abstract_id=6097646. 1,372 participants; incorrect AI advice followed in 79.8% of cases; confidence increased by 11.7 percentage points even when the AI was wrong; high AI trust associated with a 3.5-fold increase in the likelihood of following a faulty answer.
On entry-level employment: Brynjolfsson, E. et al. (2025). Cited in Stanford HAI, AI Index Report 2026, Ch. 4, Figs. 4.4.29-30. Employment for workers aged 22-25 in AI-exposed occupations fell approximately 16-20% from 2022 peaks, while headcount for older groups continued to grow. Massenkoff, M. & McCrory, P. (2026). Labor market impacts of AI. Anthropic Economic Index. anthropic.com/research/labor-market-impacts. Complementary signal: -14% job-finding rate for the same age group. On learning penalties: Shen, C. & Tamkin, A. (2025). Cited in Stanford HAI, AI Index Report 2026, Ch. 4, Fig. 4.4.27. Software engineers who relied heavily on AI for learning showed no measurable speed improvement and faced measurable learning penalties.
Brynjolfsson, E., Li, D. & Raymond, L. (2025). Generative AI at Work. Quarterly Journal of Economics, 140(2), 889-942. NBER Working Paper 31161. nber.org/papers/w31161. The 34% productivity gain for novice and low-skilled workers is the empirical basis for the counterargument. The study also provides suggestive evidence that AI disseminates the tacit knowledge of more experienced workers to less experienced colleagues — but only when the less experienced worker is actively engaged with the task, not when they are passively receiving completed outputs.
Vectara Hallucination Leaderboard (November 2025 update). On grounded summarisation tasks, leading models now achieve below 1% hallucination rates. On open-ended factual tasks, reasoning models perform substantially worse: OpenAI o3 hallucinated at 33-51% on SimpleQA/PersonQA, compared to 16% for its predecessor o1; DeepSeek-R1 hallucinated at 14.3% versus 3.9% for its base model. The divergence between anchored and open-ended performance is documented in: Graffius, S.M. (2026). Are AI Hallucinations Getting Better or Worse? scottgraffius.com.